Writing fast queries
There is a lot that goes into writing queries that run quickly and I've been struggling with how to teach this. Below are a few of the things I strive for when writing queries. These are just basic things that I attempt to do every time I write a query. Every time. Even when I'm just looking for some data in a dev environment I think about these. If I'm doing a query in DEV, it's likely to end up in some code in production. It may even just happen with the dynamic code generated by an APEX Interactive Report. If I need to do it, someone else will as well.
Note: I use Oracle databases. This may apply to others, but it may not. YMMV. Also note that Oracle Database 23c may make some of these things unnecessary, but we aren't there yet.
Many of the items below address the same goal: avoid reading the table. That's right, many queries don't require the database to read the table--it only has to read the index. At worst, though, you want to limit reading data from the table to the specific rows you are interested in (or possibly just a few rows for each row that interests you). I have not arranged these in order of importance. They are all important. But…read to the end, because the last one is super important. So is the first one. And the fifth…the ninth…the fourth…
Have a LOT of test data in your development environment. I know, this is not actually writing a query, but having a lot of test data in your development environment will keep it top of mind. Every time you add new tables in your development environment, use the APEX Data Generator to add 10,000 rows, or maybe 100,000. Create a blueprint from existing tables. Then use "Fast Insert Into" to put in a lot of data. The whole process can be done in just a couple of minutes. APEX Instant Tips Episode 85
Use the join keyword in your SQL (sometimes called ANSI syntax). You don't have to use "join", but for me, this makes the next point more obvious.
Both sides of the join condition should have indexed columns. For example:
select d.dname, e.ename
from emp e
inner join dept d on d.deptno = e.deptno
should have indexes on d.deptno and e.deptno. If the join has an "and" condition, it may be helpful to have an index on both columns within all of the conditions.
Note: foreign key (FK) columns are typically the columns found in a join. Every FK column should have an index. Every one. Always. My friend Rich Soule wrote a great query to find missing FK indexes. Check it out: https://carsandcode.com/2023/09/01/finding-unindexed-foreign-keys-in-oracle-now-with-index-creation-ddl/
Note the note at the end--if you dont' have DBA privs, replace dba_ with all_.
Oracle APEX also has a report in SQL Workshop > Utilities > Object Reports that will show missing FK indexes.Join columns should have the same data type. If they do not, explicitly cast the most restrictive column to the least restrictive (which is the only safe way to do it). So, let's assume emp.deptno is a number and dept.deptno is a varchar2. This results in
select d.dname, e.ename
from dept d
inner join emp e on to_char(e.deptno) = d.deptno
Then make sure there is a function-based index on emp.deptno with the corresponding cast. Better still, fix the data model so these columns have the same data type (if at all possible).If you frequently do a max or min on a column, it should have an index. Better still, if your max or min column is related to another column, create an index with both columns. For example
select p.name project_name, cr.created latest_code_review
from project p
left join code_review cr
on cr.project_id = p.project_id
and cr.created = (select max(cr2.created)
from code_review cr2
where cr2.project_id = p.project_id)
in addition to any other indexes, you should have one index on CODE_REVIEW with both columns: PROJECT_ID and CREATED. The order matters*:
create index code_review_idx2 on code_review (project_id,created);Corollary: If you do a group by or aggregation you may also want an index on both columns:
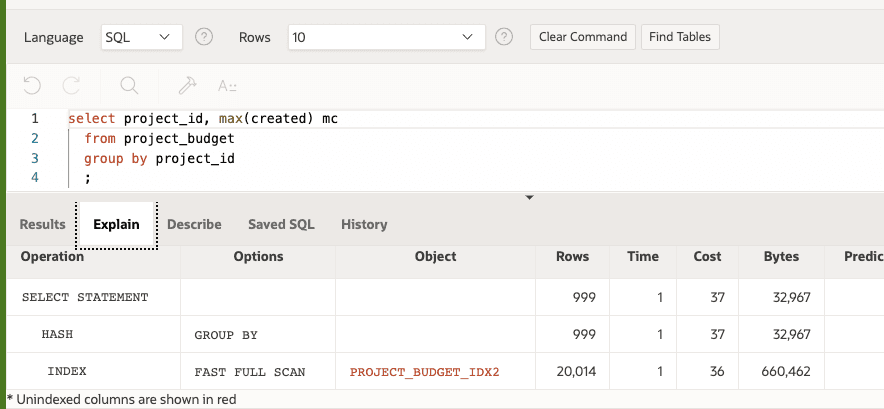
select project_id, max(created) mc
from project_budget
group by project_id
should have the same index as above. With the right index, this query will only read the index, not the table. In the image at the top of this blog post you can see that the query only accesses the index. It does a FAST FULL SCAN of the index and never reads the table. I'm going to repeat this: with the right index, this query NEVER reads the project_budget table. It only reads the index. That's a fast query!Make excessive use of scalar subqueries when you are calling PL/SQL functions. Just get in the habit of always using a scalar subquery in this scenario. Just always do it. If it is in the select portion, use a scalar subquery. If it is in the predicate, use a scalar subquery:
select empno, ename,
(select my_function(empno) from dual) my_result -- this is it
from emp
where salary > (select get_salary_max(deptno) from dual) -- and this
Just always do it. Sure, maybe sometimes it won't help, but it almost always helps and almost never hurts. (And, yes, I know that the first example above probably won't help, but just get in the habit and do it anyway. If you already know that first part won't help, this blog post may not be for you.)Sometimes scalar subqueries are faster than joins with a group by. Sometimes they are not. (I'm talking about SQL aggregations here--not calls to PL/SQL functions as discussed above.) It depends on a lot of things. If one way is slow for your use case, give the other a try. Note: this is a good reason to have a LOT (a representative amount) of data in your development environment.
Which of these will be faster?
select d.deptno,
d.dname,
(select count(*) from emp e where e.deptno = d.deptno) num_emps
from dept d
where ....
or
select d.deptno,
d.dname,
count(e.empno) num_emps
from dept d
left join emp e on e.deptno = d.deptno
where ....
group by d.deptno, d.dname
I don't know. I would need to try it out based upon a representative set of data. The where clause has a lot to do with it as does the number of rows in each table.Avoid writing one query when it really should be two (or more) queries.
select ...from ...where my_indexed_column = :P2_BLAHand my_other_indexed_column =nvl(:P2_BLAH_2, my_other_indexed_column)Oh, that is ugly, very very ugly. It would be better like this:
select ...from ...where my_indexed_column = :P2_BLAHand (my_other_indexed_column = :P2_BLAH_2 or :P2_BLAH_2 is null)
or possibly as a UNION ALL
select ...from ...where my_indexed_column = :P2_BLAHand my_other_indexed_column = :P2_BLAH_2
UNION ALL
select ...from ...where my_indexed_column = :P2_BLAHand my_other_indexed_column is null
But really, it should be two queries.
When:P2_BLAH_2 is nullit should beselect ...from ...where my_indexed_column = :P2_BLAHAnd when
:P2_BLAH_2 is not nullit should beselect ...from ...where my_indexed_column = :P2_BLAHand my_other_indexed_column = :P2_BLAH_2Wait! I know many people do it the first (wrong) way because they are using an APEX report and they just don't realize that you can have a function returning query. In that case, you would have
return 'select ...from ...where my_indexed_column = :P2_BLAH '|| case when :P2_BLAH_2 is not null then
' and my_other_indexed_column = :P2_BLAH_2 '
else null
end;Oh boy someone is going to ask "Why?" I'll add that below.** APEX Instant Tips Episode 52
It is almost redundant to note this based upon the 9 items above, but it's important to explicitly state this. No matter how big and bad your query is, it can viewed in smaller parts. Especially if you use ANSI syntax you can follow this rule more easily. So here it is, #10: Every join and every where clause should include an indexed column in a way that can use the index (see 4, 5, and 9).***
While you don't want to overload your system with indexes, if you are frequently using something in the join or where clause, it may be beneficial to have an index on that column (or that combination of columns). If it frequently involves a function, you may want a function-based index.
create index person_last_name_idx on person (upper(last_name));Unless you have explicitly defined a function based index, the database cannot use an index on a column if it is wrapped in a function. I recently saw this:
where trim(art_code) = :P10_ART_CODE
It was done because art_code was defined in the database as char(6). First, it’s 2024. We should all be using varchar2, not char. But, short of changing the column, this should be written like this:where art_code = rpad(:P10_ART_CODE, 6, ' ')
or possiblywhere art_code = rpad(trim(:P10_ART_CODE), 6, ' ')
The column art_code will almost certainly have an index on it. It likely will not have a function based index on it (because if someone is still using char(6) they probably are not using function based indexes). So, the first example can’t use the index. The following two can.
P.S. Hashnode needs to have a better way to insert code into an ordered list. I stopped at 12 because it is such a pain to format this.
*Why does the order matter? A composite (aka multi-column) index is a B-tree index just like a single-column index, and keeps the data in a sorted list (a binary tree that is super fast to traverse). The order of the columns in the index determine the sort order of the B-tree. So, INDEX1 with (product_id, created) can rapidly find all of the created dates for a particular product_id. But, INDEX2 with (created, product_id) can not. INDEX2, however, can find all product_ids where created = to_date('01-JAN-2001', 'dd-MON-yyyy') very quickly, though. Oracle introduced index skip-scanning close to two decades ago. It does some magic to be able to use INDEX1 and INDEX2 in a broader way than my simple description above, but it still isn't as good as having the right order for the job.
**Why should you break this into two queries? If it is one query, Oracle is only going to parse and create a query plan once for a query. It then re-uses the query plan every time it sees that same query. The first time it generates a query plan it peeks at the bind variables to decide what indexes to use (bind variable peeking, look it up). So, if :P2_BLAH_2 is null the first time it runs the query, it will use the index on MY_INDEXED_COLUMN...and then it will continue to use that query plan, even if :P2_BLAH_2 is not null in every subsequent run of the query. It might be that the index on MY_OTHER_INDEXED_COLUMN is a much better choice. It won't matter, Oracle won't use it. By breaking it into 2 queries, Oracle will parse both, define the best plan for each, and the re-use that correct plan each time the optimizal query is executed.
***I sometimes get the response, "But I don't know what indexes are on the table. That's the DBA's job." My answer (yes, I'm just this scary), "You're wrong. That is your job. You need to know what the indexes are. And if there aren't indexes, at a minimum you need to suggest an index to your DBA."